Grundlagen des Relationalen Modells
Nachdem wir im vorherigen Kapitel Datenbanken als Lösung für strukturierte Datenhaltung kennengelernt und PostgreSQL installiert haben, wird es jetzt konkret: Wie werden Daten in einer relationalen Datenbank organisiert?
Die Antwort: In Tabellen!
Das relationale Modell
Eine relationale Datenbank organisiert Daten in Tabellen (auch Relationen genannt). Jede Tabelle besitzt einen Namen (Relationennamen) und besteht aus:
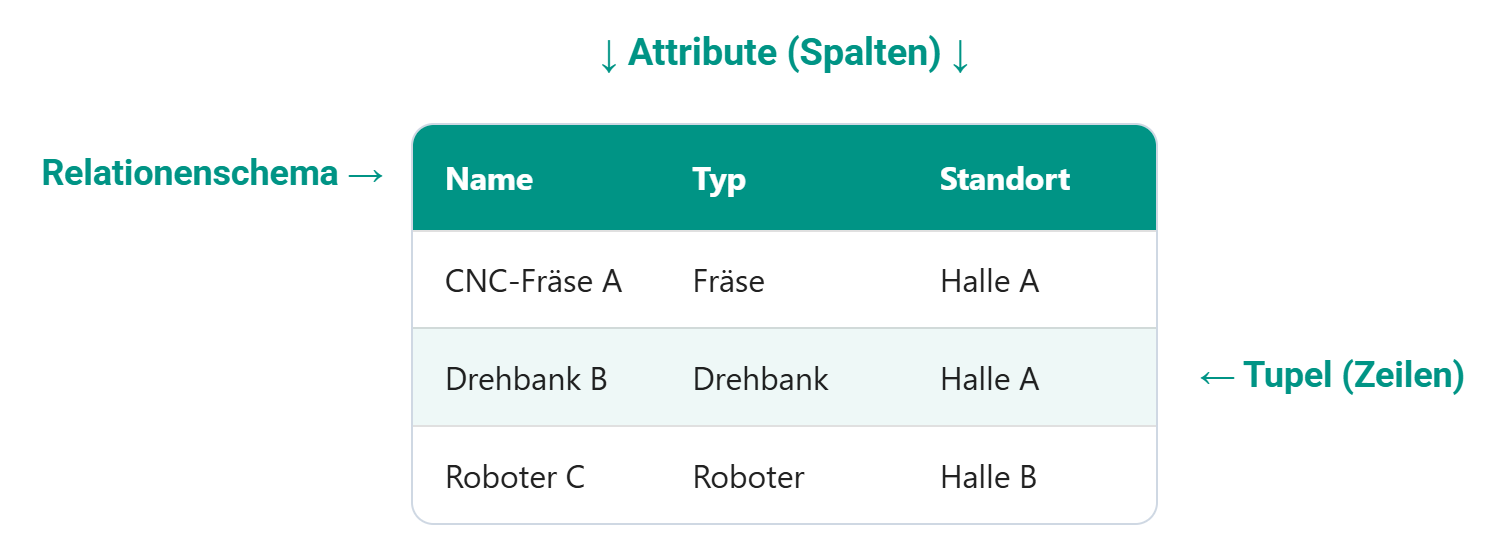
Relationale Datenbank
Eine Relationale Datenbank wird wiefolgt beschrieben:
- Tupel (auch Zeilen oder Datensätze genannt) - repräsentieren einzelne Objekte oder Einträge
- Attribute (auch Spalten oder Felder genannt) - beschreiben Eigenschaften dieser Objekte
- Relationenschema - Menge von Attributen
- Relationenname - Name der Tabelle
Datentypen in PostgreSQL
Jede Spalte einer Tabelle hat einen Datentyp, der festlegt, welche Art von Daten gespeichert werden kann. PostgreSQL bietet eine Vielzahl von Datentypen (siehe Dokumentation) - wir konzentrieren uns zunächst auf die wichtigsten:
Textdaten
Zahlen
Signed / Unsigned
Generell unterschiedet man bei ganzzahligen Datentypen zwischen signed (vorzeichenbehaftet) und unsigned (vorzeichenlos):
Signed (vorzeichenbehaftet):
- Kann positive und negative Zahlen speichern
- Beispiel
INTEGER: -2.147.483.648 bis +2.147.483.647 - Das erste Bit (Vorzeichenbit) bestimmt, ob die Zahl positiv oder negativ ist
Unsigned (vorzeichenlos):
- Kann nur positive Zahlen speichern (inkl. 0)
- Würde bei
INTEGERtheoretisch 0 bis 4.294.967.295 ermöglichen
Wichtig: PostgreSQL unterstützt standardmäßig keine unsigned-Typen!
Datum & Zeit
Sonstige
Der Primärschlüssel
Stellen wir uns vor, ein Maschinenbau-Zulieferer hat zwei Produkte mit der Bezeichnung "Hydraulikzylinder Standard". Beide kosten 450 Euro und gehören zur Kategorie "Hydraulik". Wie können wir diese beiden Produkte in unserer Datenbank eindeutig voneinander unterscheiden? Was passiert, wenn wir eine Bestellung für das erste Produkt erfassen wollen - wie weiß die Datenbank, welches der beiden gemeint ist?
Genau hier kommt der Primärschlüssel (engl. Primary Key) ins Spiel!
Ein Primärschlüssel ist eine Spalte (oder eine Kombination mehrerer Spalten), die jeden Datensatz in einer Tabelle eindeutig identifiziert. Er funktioniert wie eine Artikelnummer oder Seriennummer: Jedes Produkt, jeder Auftrag, jede Bestellung erhält einen einzigartigen Wert, über den es jederzeit zweifelsfrei identifiziert werden kann.
In unserem Beispiel würden wir den beiden Hydraulikzylindern unterschiedliche Produkt-IDs zuweisen - etwa produkt_id = 101 für das erste und produkt_id = 105 für das zweite Produkt. Selbst wenn beide dieselbe Bezeichnung, Kategorie und denselben Preis haben, sind sie durch ihre ID eindeutig unterscheidbar.
Primärschlüssel (Primary Key)
Ein Primärschlüssel ist ein Attribut (oder eine Kombination von Attributen), das jeden Datensatz in einer Tabelle eindeutig identifiziert.
Eigenschaften eines Primärschlüssels:
- Eindeutig - Kein Wert darf in der Tabelle doppelt vorkommen
- Nicht NULL - Jeder Datensatz muss einen Wert haben (leere Einträge sind nicht erlaubt)
- Unveränderlich - Sollte sich idealerweise nie ändern, um Konsistenz zu gewährleisten
Beispiele aus der Praxis:
- Produkt-ID für Artikel (z.B.
101,102, ...) - Auftragsnummer für Bestellungen (z.B.
AUF-2024-00123) - Artikelnummer für Lagerteile (z.B.
HYD-001,PNE-042) - Kunden-ID für Geschäftspartner (z.B.
K1042)
Warum sind Primärschlüssel wichtig?
Ohne Primärschlüssel würde es in der Datenbank schnell zu Chaos kommen. Ohne eindeutige Identifikation wäre eine verlässliche Datenverwaltung unmöglich. Der Primärschlüssel sorgt dafür, dass:
- Datensätze eindeutig identifiziert werden können
- Verknüpfungen zwischen Tabellen funktionieren (mehr dazu später bei Fremdschlüsseln)
- Keine Duplikate entstehen können
- Daten konsistent bleiben, selbst wenn andere Werte geändert werden
In der Praxis verwendet man häufig eine fortlaufende Nummer (1, 2, 3, ...) als Primärschlüssel, da diese automatisch eindeutig ist und sich nie ändert - selbst wenn die Produktbezeichnung oder der Preis später angepasst wird.

Erstellen einer Tabelle
Nun wollen wir in die Praxis einsteigen und unsere erste Tabelle erstellen. In diesem Kapitel verwenden wir als Beispiel einen Produktkatalog eines Maschinenbau-Zulieferers.
Datenbankgrundlage erstellen
Bevor wir starten, erstellen wir eine neue Datenbank für unser Beispiel. Dazu verbinden wir uns zuerst zu einer bereits bestehenden Datenbank unseres Servers. Dafür sollten wir bereits die Datenbanken produktions_db (aus dem vorigen Kapitel) und postgres (standardmäßig vorhanden) haben:
Verbindung zur Datenbank
Option 1: pgAdmin
Wechsle zu pgAdmin in das PSQL Tool Workspace und wähle die Datenbank produktions_db oder postgres aus.
Option 2: Terminal / Kommandozeile
Alternativ kannst du über das Terminal (macOS) oder die Kommandozeile (Windows) die Verbindung herstellen:
psql -h localhost -p 5432 -U postgres -d produktions_db
Anschließend erstellen wir eine neue Datenbank für unser Beispiel in diesem Kapitel:
Zulieferer Datenbank erstellen
-- Datenbank erstellen
CREATE DATABASE zulieferer_db;
-- Mit der Datenbank verbinden
\c zulieferer_db
You are now connected to database "zulieferer_db" as user "postgres"
Der Befehl \c ist ein psql-Befehl, der uns zur angegebenen Datenbank wechselt.
Erstellen (CREATE TABLE)
Beim Erstellen der Tabelle verwenden wir den Befehl CREATE TABLE. Nach dem Befehl folgt der Name der Tabelle und anschließend die Attribute der Tabelle in Klammern. Jedes Attribut hat einen Namen und einen Datentyp und wird durch ein Komma getrennt.
CREATE TABLE tabellenname (
attribut1 typ,
attribut2 typ,
...
);
Produktkatalog
CREATE TABLE produkte ( --(1)!
produkt_id INTEGER PRIMARY KEY, --(2)!
produktname VARCHAR(100), --(3)!
kategorie VARCHAR(50), --(4)!
preis NUMERIC(10,2), --(5)!
lagerbestand INTEGER, --(6)!
lieferant VARCHAR(100) --(7)!
);
- Erstelle eine Tabelle mit dem Namen "produkte"
- Spalte für die Produkt-ID (Primärschlüssel = eindeutig!)
- Produktname (max. 100 Zeichen)
- Produktkategorie (z.B. "Hydraulik", "Pneumatik", max 50 Zeichen)
- Preis (10 Gesamtstellen, 2 Nachkommastellen)
- Aktueller Lagerbestand (ganze Zahl)
- Name des Lieferanten (max 100 Zeichen)
CREATE TABLE
Den Primärschlüssel haben wir dabei mit Hilfe des Befehls PRIMARY KEY auf das Attribut produkt_id gesetzt.
Wenn der Befehl erfolgreich ausgeführt wurde, sollte die Tabelle in der Datenbank angezeigt werden (Default Workspace > ... > zulieferer_db > Schemas > public > Tables).
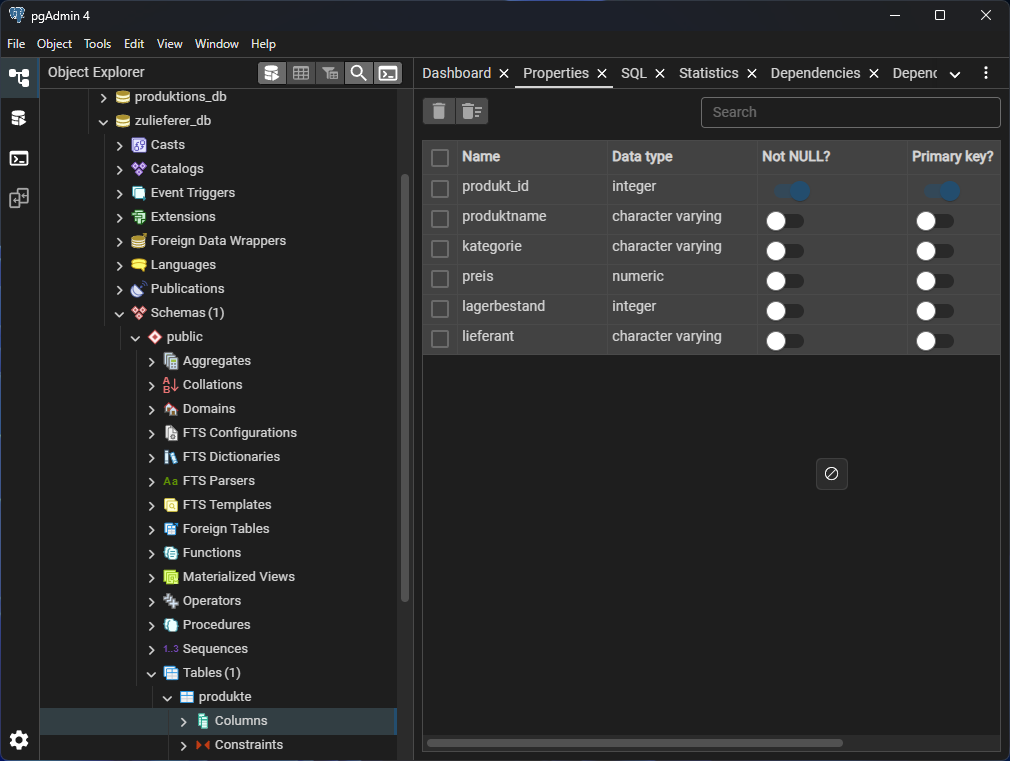
Daten einfügen (INSERT)
Eine leere Tabelle ist meist nicht das Ziel. Daher müssen wir uns nun ansehen, wie wir Daten (Zeilen / Tupel) in unsere nun bestehende Tabelle einfügen können. Dazu gibt es in SQL den INSERT Befehl.
INSERT INTO tabellenname (attribut1, attribut2, ...)
VALUES (wert1, wert2, ...);
Produkte einfügen
INSERT INTO produkte (
produkt_id, produktname, kategorie, preis, lagerbestand, lieferant
)
VALUES
(101, 'Hydraulikzylinder Standard', 'Hydraulik', 450.00, 25, 'Bosch Rexroth'),
(102, 'Pneumatikventil 5/2-Wege', 'Pneumatik', 89.50, 50, 'Festo AG'),
(103, 'Kugelgewindetriebe KGT40', 'Mechanik', 780.00, 12, 'THK GmbH'),
(104, 'Servomotor 3kW', 'Antriebstechnik', 1250.00, 8, 'Siemens AG'),
(105, 'Näherungsschalter induktiv', 'Sensorik', 35.90, 100, 'Sick AG');
INSERT 0 5
Datentyp beachten
- Textwerte müssen in einfachen Anführungszeichen stehen:
'Text' - Zahlen stehen ohne Anführungszeichen:
42oder123.45
Daten abfragen (SELECT)
Nachdem wir nun eine befüllte Tabelle vor uns haben, ist die nächste Aufgabe klar: wir wollen die Daten aus der Datenbank auslesen/abrufen. Dazu verwenden wir den SELECT Befehl:
SELECT * FROM tabellenname;
Alle Produkte anzeigen
SELECT * FROM produkte;
produkt_id | produktname | kategorie | preis | lagerbestand | lieferant
------------+------------------------------+------------------+---------+--------------+----------------
101 | Hydraulikzylinder Standard | Hydraulik | 450.00 | 25 | Bosch Rexroth
102 | Pneumatikventil 5/2-Wege | Pneumatik | 89.50 | 50 | Festo AG
103 | Kugelgewindetriebe KGT40 | Mechanik | 780.00 | 12 | THK GmbH
104 | Servomotor 3kW | Antriebstechnik | 1250.00 | 8 | Siemens AG
105 | Näherungsschalter induktiv | Sensorik | 35.90 | 100 | Sick AG
(5 rows)
Der * Operator
Das * (Sternchen) ist ein Platzhalter für "alle Spalten". Es ist praktisch für schnelle Abfragen, aber in der Praxis sollte man die benötigten Spalten explizit angeben, da sonst unnötig Daten übertragen werden müssen.
SELECT attribut1, attribut2 FROM tabellenname;
Bestimmte Spalten anzeigen
SELECT produktname, kategorie, preis FROM produkte;
produktname | kategorie | preis
-----------------------------+------------------+--------
Hydraulikzylinder Standard | Hydraulik | 450.00
Pneumatikventil 5/2-Wege | Pneumatik | 89.50
Kugelgewindetriebe KGT40 | Mechanik | 780.00
Servomotor 3kW | Antriebstechnik | 1250.00
Näherungsschalter induktiv | Sensorik | 35.90
(5 rows)
Übung ✍️
Jetzt geht es darum, das Erlernte in einem praxisnahen Projekt anzuwenden. In diesem und den folgenden Kapiteln baust du Schritt für Schritt ein Produktionsplanungssystem für einen mittelständischen Fertigungsbetrieb auf.
Die TecGuy GmbH ist ein mittelständisches Fertigungsunternehmen, das Präzisionsteile für die Automobilindustrie herstellt. Das Unternehmen möchte ein digitales System zur Verwaltung seiner Produktionsaufträge und Produktionsmaschinen aufbauen.
In diesem Kapitel startest du mit den ersten beiden Tabellen: Produktionsaufträge und Maschinen.
Übungsvorbereitung - Datenbank zurücksetzen
Falls du neu startest oder die Übung wiederholen möchtest, führe dieses Setup aus. Es löscht alle bestehenden Daten und erstellt den korrekten Ausgangszustand für dieses Kapitel.
-- Zu anderer Datenbank wechseln
\c postgres
-- Datenbank löschen falls vorhanden
DROP DATABASE IF EXISTS produktionsplanung_db;
Hinweis: Ab jetzt kannst du direkt mit Aufgabe 1 starten.
Aufgabe 1: Datenbank und Tabellen erstellen
Schritt 1: Erstelle eine neue Datenbank für das Projekt:
CREATE DATABASE produktionsplanung_db;
\c produktionsplanung_db
Schritt 2: Erstelle eine Tabelle produktionsauftraege mit folgenden Spalten:
auftrag_id(INTEGER, Primärschlüssel)auftragsnummer(VARCHAR(20))kunde(VARCHAR(100))produkt(VARCHAR(100))menge(INTEGER)startdatum(DATE)lieferdatum(DATE)status(VARCHAR(20))maschinen_id(INTEGER)
Schritt 3: Erstelle eine Tabelle maschinen mit folgenden Spalten:
maschinen_id(INTEGER, Primärschlüssel)maschinenname(VARCHAR(100))maschinentyp(VARCHAR(50))produktionshalle(VARCHAR(50))anschaffungsjahr(INTEGER)maschinenstatus(VARCHAR(20))wartungsintervall_tage(INTEGER)
💡 Tip anzeigen
Verwende CREATE TABLE
⚡ Lösung anzeigen
-- Tabelle für Produktionsaufträge
CREATE TABLE produktionsauftraege (
auftrag_id INTEGER PRIMARY KEY,
auftragsnummer VARCHAR(20),
kunde VARCHAR(100),
produkt VARCHAR(100),
menge INTEGER,
startdatum DATE,
lieferdatum DATE,
status VARCHAR(20),
maschinen_id INTEGER
);
-- Tabelle für Produktionsmaschinen
CREATE TABLE maschinen (
maschinen_id INTEGER PRIMARY KEY,
maschinenname VARCHAR(100),
maschinentyp VARCHAR(50),
produktionshalle VARCHAR(50),
anschaffungsjahr INTEGER,
maschinenstatus VARCHAR(20),
wartungsintervall_tage INTEGER
);
Aufgabe 2: Daten einfügen
Teil A: Füge folgende Maschinen in die Tabelle maschinen ein:
Teil B: Füge folgende Produktionsaufträge in die Tabelle produktionsauftraege ein:
💡 Tip anzeigen
Verwende INSERT INTO & VALUES
⚡ Lösung anzeigen
-- Maschinen einfügen
INSERT INTO maschinen (
maschinen_id, maschinenname, maschinentyp, produktionshalle,
anschaffungsjahr, maschinenstatus, wartungsintervall_tage
)
VALUES
(1, 'CNC-Fraese Alpha', 'CNC-Fraese', 'Halle A', 2020, 'Aktiv', 90),
(2, 'Drehbank Delta', 'Drehbank', 'Halle A', 2018, 'Aktiv', 120),
(3, 'Presse Gamma', 'Presse', 'Halle B', 2019, 'Wartung', 60),
(4, 'Schweissroboter Beta', 'Schweissroboter', 'Halle C', 2021, 'Aktiv', 90);
-- Produktionsaufträge einfügen
INSERT INTO produktionsauftraege (
auftrag_id, auftragsnummer, kunde, produkt, menge,
startdatum, lieferdatum, status, maschinen_id
)
VALUES
(1, 'AUF-2024-001', 'BMW AG', 'Getriebegehäuse', 500, '2024-04-01', '2024-04-15', 'In Produktion', 1),
(2, 'AUF-2024-002', 'Audi AG', 'Kurbelwelle', 200, '2024-04-10', '2024-04-20', 'Geplant', 2),
(3, 'AUF-2024-003', 'Mercedes-Benz', 'Pleuelstange', 350, '2024-04-05', '2024-04-18', 'In Produktion', 2),
(4, 'AUF-2024-004', 'Porsche AG', 'Kolben', 150, '2024-04-12', '2024-04-25', 'Geplant', 4);
Aufgabe 3: Daten abfragen
Führe folgende Abfragen durch:
- Zeige alle Produktionsaufträge an.
- Zeige nur Auftragsnummer, Kunde und Produkt der Aufträge an.
- Zeige alle Maschinen an.
- Zeige nur Maschinenname und Maschinentyp der Maschinen an.
💡 Tip anzeigen
SELECT&*SELECTSELECT&*SELECT
⚡ Lösung anzeigen
-
Alle Produktionsaufträge:
SELECT * FROM produktionsauftraege; -
Nur bestimmte Spalten:
SELECT auftragsnummer, kunde, produkt FROM produktionsauftraege; -
Alle Maschinen:
SELECT * FROM maschinen; -
Nur Maschinenname und Typ:
SELECT maschinenname, maschinentyp FROM maschinen;
In den folgenden Kapiteln werden wir:
- Beziehungen zwischen Tabellen erstellen (Foreign Keys)
- Weitere Tabellen hinzufügen (Wartungsprotokolle, Ersatzteile, Lager)
- Komplexe Abfragen durchführen (Joins, Aggregationen, Subqueries)
- Datenintegrität sicherstellen (Constraints, CHECK, UNIQUE)
- Transaktionen für sichere Operationen nutzen
- Daten manipulieren (UPDATE, DELETE, ALTER TABLE)
Am Ende haben wir ein vollständiges, funktionsfähiges Produktionsplanungssystem!
Zusammenfassung 📌
- Das relationale Modell organisiert Daten in Tabellen mit Zeilen und Spalten
- Jede Spalte hat einen Datentyp (VARCHAR, INTEGER, NUMERIC, DATE, ...)
- Ein Primärschlüssel identifiziert jeden Datensatz eindeutig und darf nicht NULL sein
CREATE TABLEerstellt eine neue Tabelle mit definierter StrukturINSERT INTOfügt neue Datensätze in eine Tabelle einSELECTfragt Daten aus einer Tabelle abSELECT *zeigt alle Spalten, währendSELECT attribut1, attribut2nur bestimmte Spalten zeigt
Im nächsten Kapitel lernen wir, wie wir Daten gezielt filtern, sortieren und aggregieren können - die wahre Macht von SQL!